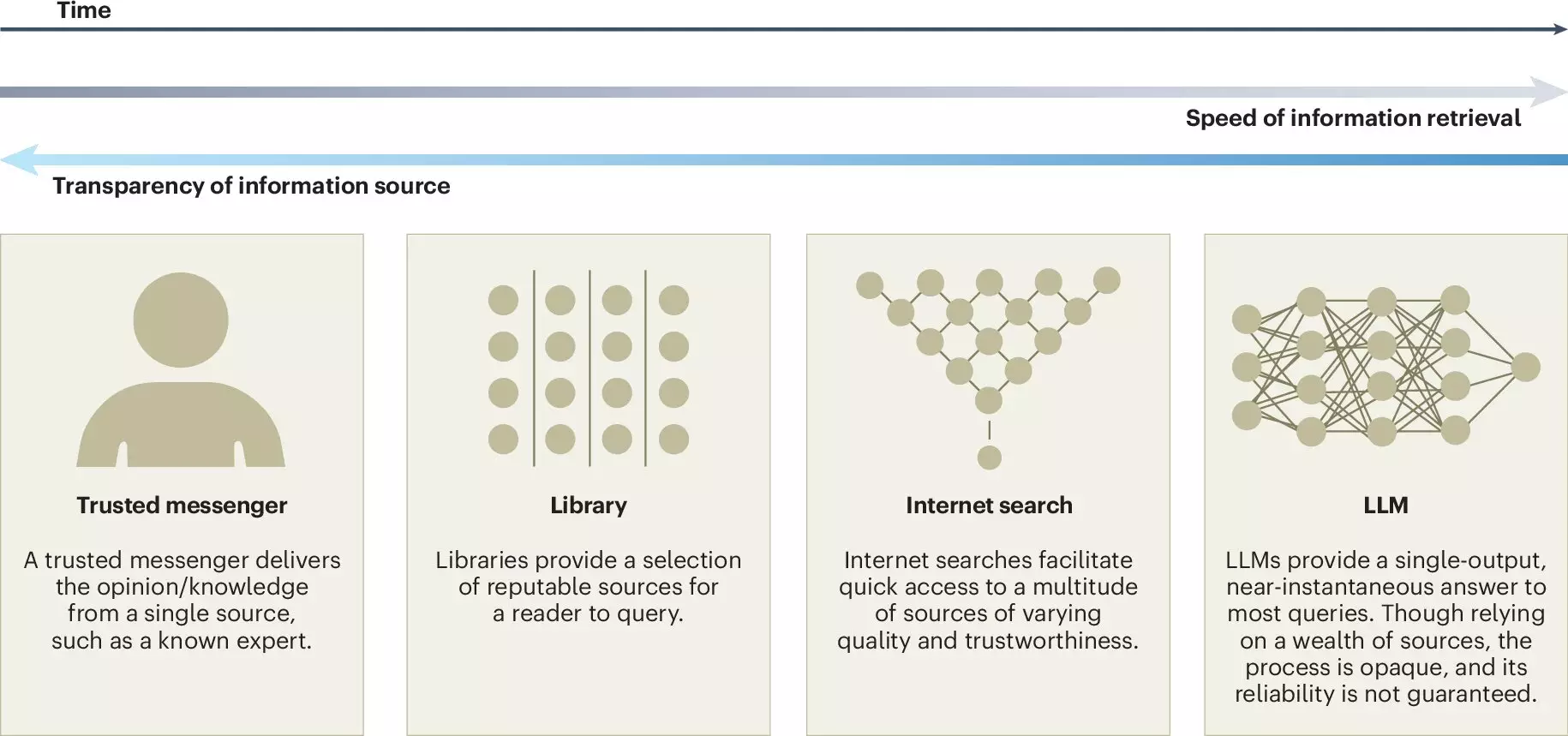
In recent years, large language models (LLMs) have emerged as transformative tools that are reshaping how we interact with information and engage in collective decision-making. Technologies such as ChatGPT epitomize this revolutionary advancement, offering individuals and organizations unprecedented capabilities in text generation and analysis. A recent study published in *Nature Human Behaviour* underscores both the potential benefits and inherent risks associated with employing LLMs in our daily deliberative processes. Conducted by a multidisciplinary team from prestigious institutions like Copenhagen Business School and the Max Planck Institute for Human Development, this research prompts vital conversations among policymakers, educators, and technologists on how to best utilize LLMs to enhance collective intelligence without compromising its integrity.
At its core, collective intelligence refers to the synergistic effect that arises from a group’s combined knowledge and experiences. When individuals collaborate, they can often achieve outcomes that none could have accomplished alone, thus amplifying their problem-solving capabilities. This principle is in play across various contexts — from small teams in corporate settings to the expansive networks of contributors on platforms like Wikipedia. Collective intelligence thrives on diversity, where differing perspectives contribute to richer discussions and better-informed conclusions. The introduction of LLMs into this dialogue serves as a double-edged sword, presenting opportunities to enhance participation while risking the dilution of unique viewpoints.
One of the most compelling advantages presented by LLMs lies in their ability to democratize information access. By employing advanced translation and writing support capabilities, these models can bridge communication gaps, enabling individuals from varied backgrounds to engage equally in discussions. This inclusivity fosters enriched idea generation and streamlines decision-making processes, allowing teams to synthesize information more efficiently. For example, LLMs can facilitate collaborative brainstorming sessions by providing relevant data, summarizing diverse opinions, and assisting in reaching a consensus.
Ralph Hertwig, a co-author of the aforementioned study, emphasizes the need for balance: “As large language models increasingly shape the information and decision-making landscape, it’s crucial to strike a balance between harnessing their potential and safeguarding against risks.” However, while these opportunities are promising, careful consideration must be given to the implications of reliance on such technology.
Despite their potential benefits, the application of LLMs is fraught with several substantial risks. A primary concern is the threat they pose to knowledge-sharing platforms like Wikipedia. As users become more reliant on LLMs for information, there is a risk of diminishing individual contributions to collective knowledge. This dependence on proprietary LLMs could ultimately undermine the openness and diversity essential to thriving online communities. The researchers point out that if LLMs draw primarily from dominant narratives and fail to account for minority viewpoints, they can inadvertently create a false consensus and perpetuate pluralistic ignorance. This scenario raises alarm bells regarding the fidelity and trustworthiness of collective intelligence processes.
Jason Burton, the study’s lead author, highlights this issue: “Since LLMs learn from information available online, there is a risk that minority viewpoints are unrepresented in LLM-generated responses.” The existence of a misleading semblance of agreement could result in the marginalization of critical but less-prominent perspectives, leading to societal biases and a homogenized knowledge base.
To navigate these challenges, the co-authors of the study advocate for a proactive approach to LLM development. They recommend increased transparency regarding the training data and methodologies employed in model creation. By implementing external audits and monitoring, LLM developers would be held accountable for the content generated and its potential societal consequences. Such measures could mitigate adverse effects and ensure that LLMs serve to complement rather than compromise collective intelligence.
Furthermore, the authors encourage researchers to reflect critically on how collective intelligence principles can inform LLM training. This includes striving for diverse representation in training datasets and recognizing the importance of credit and accountability in instances where LLMs contribute to collective outcomes.
The ongoing dialogue around the integration of large language models into our collective decision-making frameworks is crucial. As technologies evolve, so too must our understanding of their implications for human collaboration and intelligence. By harnessing the potential of LLMs while establishing safeguards against their risks, society can cultivate an enriched environment for collective intelligence to flourish. Moving forward, it is imperative that stakeholders remain vigilant, proactive, and committed to fostering a landscape where technology enhances rather than undermines our shared knowledge and decision-making capabilities.
Leave a Reply