Deep learning has become a cornerstone of modern artificial intelligence applications, renowned for its ability to learn complex patterns from vast datasets. However, the reliability of these models is often compromised by label noise—errors in the data labeling process that can lead to significant declines in classification performance during testing. Label noise can obscure the true relationships within the data, making it challenging for algorithms to learn effectively. As the field progresses, the necessity for robust techniques to mitigate the adverse effects of this noise has become paramount.
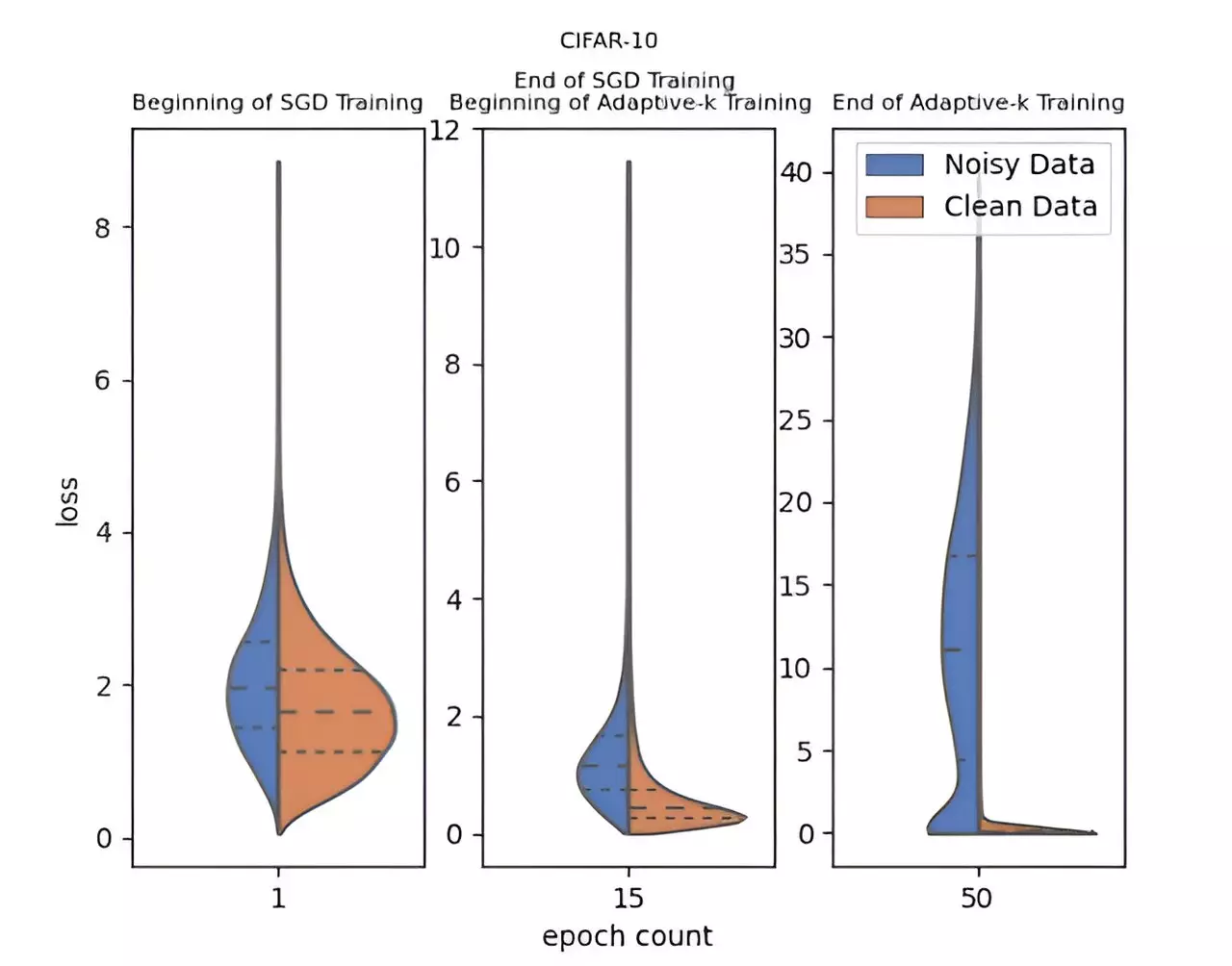
A recent breakthrough in addressing label noise comes from a dedicated research team at Yildiz Technical University, led by Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali. Their innovative approach, dubbed Adaptive-k, represents a significant step forward in optimizing the learning process for deep neural networks. Unlike traditional methodologies that typically struggle with the noisy labels pervasive in large datasets, Adaptive-k strategically selects data samples for updates during the mini-batch training. This dynamic selection is crucial for distinguishing between informative and noisy samples, ultimately enhancing the model’s learning capability.
What makes Adaptive-k particularly attractive is its simplicity and effectiveness. Unlike many alternatives, it does not impose the need for extensive prior knowledge regarding the noise ratio of the dataset, nor does it require the additional training resources often associated with other approaches. This efficiency positions Adaptive-k as a practical solution for practitioners facing the challenge of noisy datasets.
In their seminal paper published in *Frontiers of Computer Science*, the team meticulously compared the Adaptive-k methodology against established algorithms such as Vanilla, MKL, Vanilla-MKL, and Trimloss. A crucial component of their evaluation involved an Oracle scenario, where all noisy samples are explicitly identified and excluded. Their results consistently indicated that Adaptive-k provided performance outcomes that closely mirrored those of the Oracle method, demonstrating its effectiveness in managing unreliable labeling without requiring exhaustive sample pruning.
These benchmarks were rigorously tested across various datasets, including three image-based collections and four text-based corpuses. The findings were consistent and promising, suggesting that Adaptive-k outperformed its counterparts in scenarios marked by label noise.
The implications of Adaptive-k extend beyond mere performance improvements. As it can be harmonized with various optimization algorithms such as SGD, SGDM, and Adam, its versatility enhances its applicability in diverse contexts. This adaptability will be vital as researchers and developers increasingly work with datasets where noise remains an inherent challenge.
Looking ahead, the authors of the research plan to further refine the Adaptive-k framework, explore additional applications in various fields, and continue enhancing its efficacy. As the demand for dependable machine learning solutions grows, methods like Adaptive-k will likely play an essential role in fostering the next generation of robust deep learning systems capable of thriving amidst the imperfections of real-world data.
Ultimately, Adaptive-k signifies a pivotal advancement in the quest to improve deep learning in the face of label noise, underscoring the importance of innovation in achieving reliable and effective artificial intelligence.
Leave a Reply